1. 什么是跳表?

如上图所示,跳表是一种基于多级索引的有序链表,对于查找效率的提高十分明显,常用于有序数据的高效存储和检索。
1.1 跳表的结构
跳表由多个层级(Level)组成:
- 最底部(Level 0)是一个普通的有序链表,包含所有元素。
- 每一层的节点是下一层的子集,每隔一定概率(在leveldb中 p = 1/ 4)提升到上一层,形成多级索引。
一般来说,
- Level 0:包含所有元素
- Level 1:大约包含 1 / 4 的元素
- Level 2:大约包含 (1 / 4)^ 2 = 1 / 16的元素
- ……
- Level k:大约包含 (1 / 4) ^ k 的元素
K会小于限定的最高层数,每一个元素是否会移到上一层全靠运气。
leveldb中 P = 1 / 4。一般别的跳表可能会取 P = 1 / 2,这样更好理解,就像抛硬币,每个元素都抛一次,正面就往上复制一次。
1.2 为什么需要跳表
我们来看普通的链表。
15 -> 18 -> 25 -> 39 -> 55
如果要查找55,我们需要从下标0开始依次遍历5次,才能找到55,效率很低,时间复杂度O(n)。
如果使用跳表会怎么样呢?
我们先介绍跳表的查询规则:
- 从最高层H开始查找,遍历节点,查找目标元素。
- 如果没有找到目标元素,我们从当前层中小于目标元素的最后一个节点跳下去,继续查找。
- 重复这个过程,直到找到目标元素。
下面看下图,分析在跳表中如何找55。
其中 -max和max 起到了哨兵的作用。
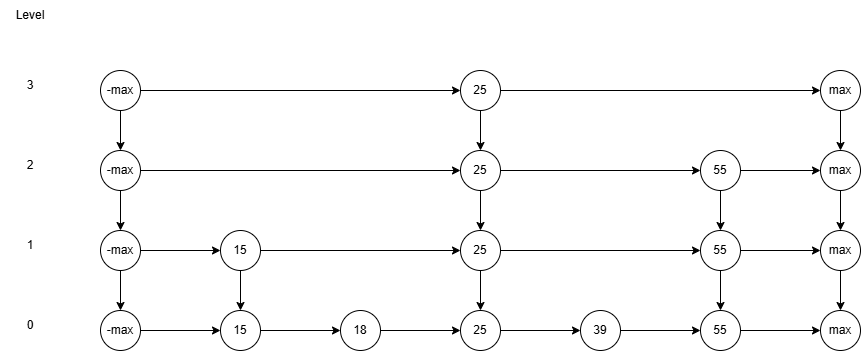
我们发现寻找55只需要遍历3个节点。
例子中因为数据量比较少,所以看不出快很多,但当数据量很大时,提升十分的显著。
1.3 跳表的复杂度分析
| 类型 | 复杂度 |
|---|---|
| 查找 | O(logn) |
| 插入 | O(logn) |
| 删除 | O(logn) |
| 空间 | O(n) |
证明个人不是很会,就不写了。
只需要知道,这种数据结构可以替代平衡树的使用。
2. Leveldb源码分析
PREVIOUSleveldb第三章 Arena源码分析
NEXTC++ 类型转化和拷贝